Welcome to the Best Text to Speech Voices – Natural TTS voices!
Amazing Text-to-Speech Technology!
World's most advanced synthetic speech technology!
We are proud to offer solutions that integrate our award-winning Text-to-Speech technology!
We develop character-full and expressive synthetic voices that can read aloud audiobooks, act in games, or even narrate fairy tales! Our synthetic voices are the perfect match for any application that needs to integrate synthesized speech, either on-the-fly or offline.
A single technology, infinite applications!
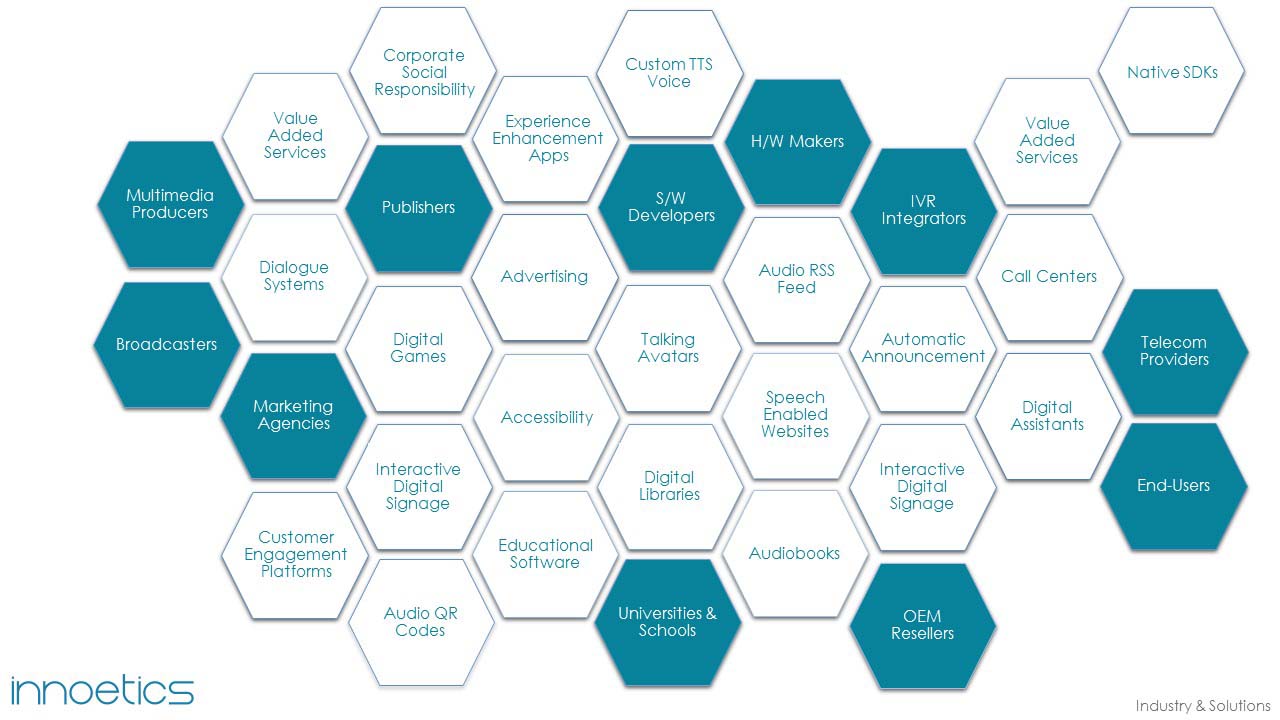
Our text to speech technology has benefited end-users, enterprises, hardware and software developers.
Click on the image to view some indicative applications of Text-to-Speech technology.